









Written by: Oluwafemi Oluseki
The African tech ecosystem, at a fast pace, is accelerating the race to integrate Artificial Intelligence. Machine learning is no longer confined to the research lab, whether it is Nairobi-based agritech startups, where computer-vision algorithms can scan and detect crop yields, or Lagos-based fintechs, where risk-assessment algorithms can be compiled into the final product. Most companies weaken at the step of transitioning a promising prototype into a solid production system though.
As the engineering teams are trying to scale these efforts, they are experiencing a giant architectural wall. The infrastructure that needs to be trained and served machine learning models is fundamentally different from the traditional web applications. Attempting to impose AI workloads on more normal, web-friendly deployment pipelines leads to the typical outcome of catastrophe: soaring cloud expenses, idle GPUs and overloaded Site Reliability Engineers (SREs).
A truly scaling architecture will require a great architectural breakthrough: Standardised Internal Developer Platforms (IDPs) designed with the special needs of Machine Learning and AI workloads in mind.
Why Standard CI/CD Fails for Machine Learning
Conventional software engineering uses a comparatively simple paradigm, which consists of write, push to version control, run automated tests, build container, and deploy.
Machine learning completely break the paradigm. The development of AI is not a one-dimensional issue that is all about Code. It is a three-dimensional process that encompasses Code, Data, and Models. In contrast to the traditional software, tests are very deterministic (pass/fail), ML models are probabilistic. It is not merely whether the code compiles, but you are continually running the outputs against huge and constantly changing datasets to ensure the statistical accuracy of the results.
A typical CI/CD pipeline has no capacity to process a 500GB training dataset. Conventional Kubernetes clusters though brilliant at scaling weight-lifting microservices were not initially intended to run long-running and stateful ML training loops with exclusive access to special hardware such as Nvidia GPUs or Google TPUs.
Also, the deployment of an ML model is not the end of the job as soon as the model is deployed. Models deteriorate with time as the real world data evolves- a phenomenon referred to as model drift. Classic surveillance devices (such as Datadog or New Relic) can inform you that a server is spiking on its CPU, but it can not inform you that your neural network has been producing biassed or incorrect predictions.
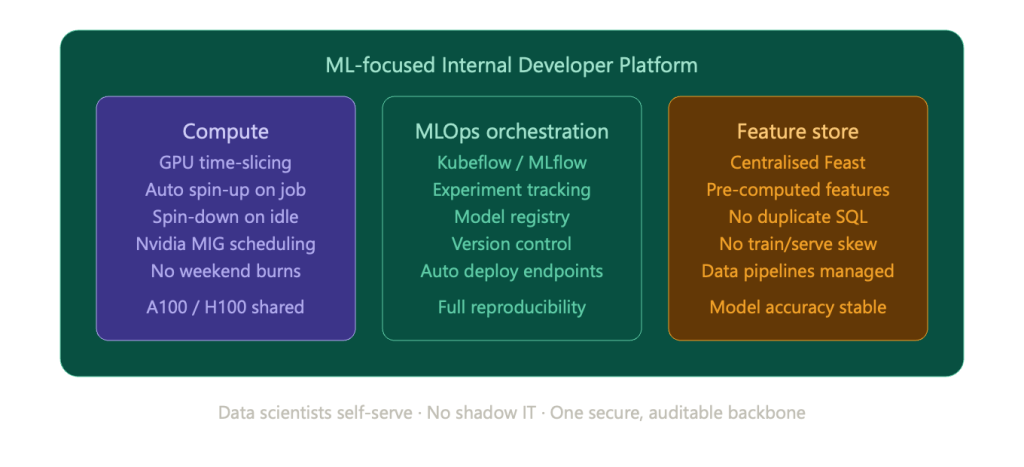
The Architecture of an ML-Focused IDP
In order to eliminate this, advanced Platform Engineering teams are developing dedicated ML-IDP. These environments are built on top of the underlying cloud infrastructure and offer a standardised abstraction layer of data science teams on a self-service basis.
However, what actually goes into the construction of an IDP in particular to AI? It involves adopting a number of infrastructural elements which are specialised:
1. Compute Abstraction and GPU Time-Slicing.
The most costly cloud resources that a startup can rent are GPUs. The biggest mistake of ad-hoc ML infrastructure is that the data scientist orders a powerful cloud instance to a notebook, and then still runs a two-hour training job, and leaves the instance idle over the weekend, which a data scientist can not afford on a startup budget, with a single instance (like Nvidia A100s or H100s) costing thousands of dollars a month. An advanced ML-IDP adopts the high-level scheduling and time-slicing (such as Nvidia Multi-Instance GPU) of a physical GPU to divide one physical GPU into several physically-isolated instances. The IDP will automatically spin up a compute only when a job is currently running and spin it down aggressively as soon as the job is complete to ensure the greatest utilisation of resource.
2. Standardised MLOps Orchestration
The IDP implements a standard form of orchestration layer instead of letting teams utilise a disjointed assortment of bespoke bash scripts and hand deployments. Platforms such as Kubeflow or MLflow are included with the platform. This offers a single system that tracks experiments, provides model registry (version control of models), and deploys inference endpoints automatically. This also ensures reproducibility; in case a regulator or auditor queries how a fintech made a decision on its credit-scoring model a half a year ago, the IDP gives the specific code, data snapshot and parameters applied.
3. Feature Stores and Data Pipelines
The quality of an ML model is no better than its data. A specialised ML-IDP has a centralised Feature Store a central vault where data engineers create, compute and store reusable features of data. They do not need to refer to the data warehouse to write the complex SQL queries to retrieve the same history of customer transactions in the data warehouse; all they do is to access the pre-computed feature in the IDP. This establishes enormous savings in computational time and avoids the much-feared training-serving skew, where the models work well in the lab, but fail in the real world as the real-life data pipelines compute features in a different way.
The ROI for Lean Engineering Teams
In the case of the African startups, the rationale behind developing (or purchasing) an ML-centric IDP is reduced to the optimisation of resources, including human and computational.
We exist in a talent market, where it is fantastically hard and costly to hire experienced MLOps engineers and Kubernetes experts. You decouple data science and DevOps by making the complexity of ML infrastructure more centralised into a standardised platform.
Data scientists do not have to open IT tickets to ask to get compute power or to find out how to construct Docker containers with CUDA drivers. They just log in IDP, ask workspace and concentrate on everything related to training models. In the meantime, the platform engineering team has a single, highly secure, and cost-efficient backbone infrastructural base, instead of tracking down the use of shadow IT in various AWS accounts. It also minimises security vulnerabilities drastically because vulnerable customer data is never stored sitting in unmonitored, non-outlined S3 buckets that were created on a whim to accomplish a specific experiment.
The companies that emerge successful without the need of the most intricate algorithms will not necessarily be the ones that introduce AI as a table stakes to compete with. The victors will be the firms that will have the infrastructure to transform the chaotic ML experimentation into a predictable, scalable, highly secure, and automated assembly line. The important initial step to that journey is to standardise your ML infrastructure with a dedicated IDP.
About the author

Oluwafemi Oluseki is a Cloud Solutions Architect and Senior Platform Engineer working across AWS and Azure, with a focus on platform engineering, security, and AI infrastructure.
He is co-founder of LimeSoft Systems, where he develops cloud-native platforms and security-focused infrastructure to support modern application delivery. His work has supported production systems used across 50+ teams and organisations, improving deployment consistency and operational reliability.
He writes and mentors within the African tech community.










