Table of contents
The internet experienced a significant disruption on Tuesday, November 18, 2025, after Cloudflare, the US internet infrastructure firm, suffered an internal failure that affected its global network. Because many services rely on Cloudflare to stay online, the outage affected millions of people and disrupted a wide range of services, from social platforms to AI tools. The incident highlighted how heavily the internet relies on a single provider and how quickly things can break when that provider experiences a core failure.
What Cloudflare actually does
To understand why the outage spread so widely, you need to know what Cloudflare does behind the scenes. Cloudflare sits between you and the websites you open. It speeds up those sites, protects them, and maintains stable connections.
When you visit a website that uses Cloudflare, your request passes through Cloudflare’s network. The system checks for threats, optimises the connection, and sends the content back to you without exposing the website’s original server. This makes websites safer and more reliable.
Cloudflare’s core functions include:
- Content delivery for speed: It operates a massive global CDN that stores cached copies of websites in data centres close to you, reducing delays.
- Security and protection: It protects websites from attacks, especially DDoS attacks, and powers Zero Trust systems that decide which users or devices should be allowed through.
- DNS management: It helps run the DNS system that turns website names into IP addresses. If this layer has issues, you may not be able to reach a site, even if the site itself is online.
- Network reliability: Cloudflare utilises an Anycast setup, where the same IP address is present in multiple data centres worldwide. Your request is routed to the closest available centre, and if one location fails, another one takes over.
What happened and who was affected
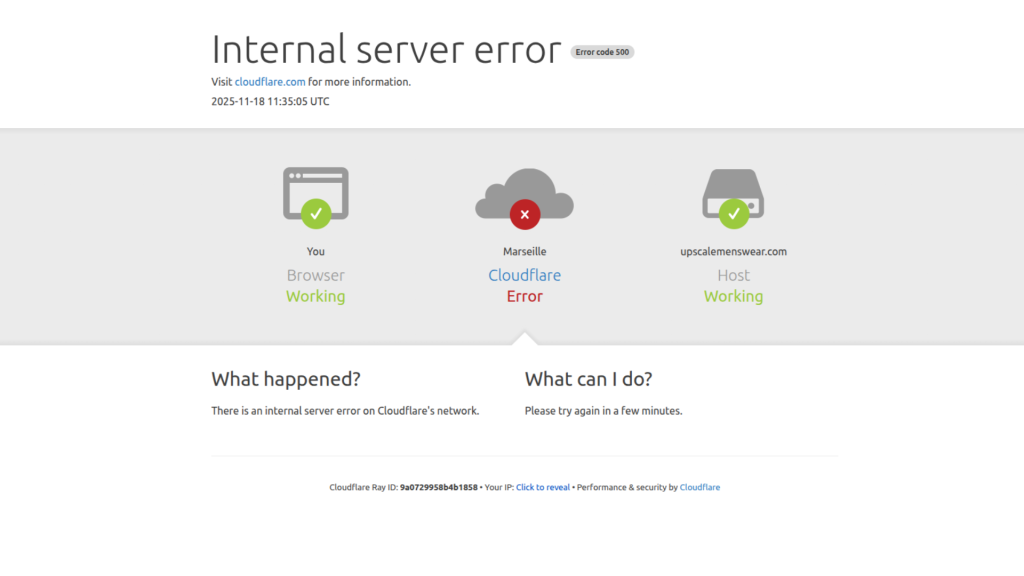
Around 11:00 UTC (12:00 WAT), websites that use Cloudflare began returning widespread 500 errors. Cloudflare’s own dashboard and API also went offline, which made it harder for the company to respond. Platforms like X, Facebook, OpenAI, and Perplexity were among the many services users could not access.
The CTO later explained that the outage was caused by a latent bug in a service powering Cloudflare’s bot mitigation system. During a routine configuration change, that bug triggered a crash in the service. From there, the failure cascaded into Cloudflare’s wider network, causing a significant degradation across multiple services.
He confirmed that this was not an attack and apologised for the disruption.
Because Cloudflare handles a vast share of global web traffic, any internal failure spreads instantly. Even services with their own backups had no protection because they still relied on Cloudflare to connect users to their platforms.
How the November 18 outage unfolded
The outage escalated from early warning signs to a global incident within minutes.
When the first signs appeared
Around 6:00 AM ET (12:00 PM WAT), outage trackers showed unusual spikes. Cloudflare confirmed it was investigating a significant network-wide issue. Users encountered 500 errors across websites that relied on Cloudflare, and platforms such as X, Facebook, and several others stopped loading.
By 11:48 UTC (12:48 PM WAT), Cloudflare publicly acknowledged that multiple customers were affected. Their dashboard and API were still offline, limiting the company’s ability to monitor and respond.
Why this was not scheduled maintenance
Cloudflare had routine maintenance planned in a few regional data centres that day, but the tasks were limited and not expected to affect global traffic. The CTO’s update confirmed that the outage was caused by a latent bug in the bot mitigation service and a routine configuration change, not by maintenance work. Once the internal service crashed, it caused a chain reaction that affected the entire network.
Why the load-balancing system failed
Cloudflare’s systems rely on continuous health checks to determine which servers are safe to route traffic to. The bot mitigation service that crashed sits deep in Cloudflare’s control layer. When it failed, it disrupted the information used by the load balancers and other critical systems.
Without accurate internal signals, the system defaulted to a conservative safety posture, treating many servers as unhealthy. Cloudflare could receive requests, but could not route them appropriately. This triggered the widespread 500 errors users saw across multiple websites.
The problem grew worse because Cloudflare’s internal tools, including the dashboard and API, were also affected. Since the failure happened in the core control layer, Cloudflare’s global redundancy could not help.
Cloudflare has now confirmed that the issue is fully resolved, and work is underway to ensure this type of failure does not occur again.
Services and platforms affected
The outage spread across multiple industries almost instantly, demonstrating the deep integration of Cloudflare into the everyday tools you use.
1. Social platforms, news, and finance
X and Facebook experienced significant downtime, leaving users unable to load timelines or pages. Financial and entertainment sites such as Letterboxd and bet365 also went offline, disrupting browsing, betting, and other activities.
2. AI and utility platforms
AI services were heavily affected. OpenAI and Perplexity displayed errors or Cloudflare challenge screens. Many users received a message asking them to unblock a Cloudflare challenge, which occurred because the security layer was unable to verify traffic after the routing logic failed. With Cloudflare’s internal tools offline, those challenges could not be processed, leaving legitimate users locked out.
3. Outage trackers
Even Downdetector, a tool people rely on to check if services are down, loaded inconsistently. This showed how dependent support tools are on the same infrastructure that was breaking.
Why a Cloudflare outage brings down so much of the internet
The outage highlighted how dependent the internet is on Cloudflare’s performance and stability. When the core control layer crashed due to the latent bug and configuration-triggered failure, the impact spread across social platforms, financial services, AI systems, and essential tools almost instantly.
Cloudflare usually keeps services online by routing traffic to the closest working data centre, but that system only works when the control layer is healthy. On November 18, the control layer collapsed. With the routing logic unreliable, Cloudflare stopped handling traffic correctly, which caused a global wave of 500 errors and access blocks.
The error messages made the issue clear:
- 500 errors indicated an internal logic failure
- Cloudflare challenges appeared because the security system entered its protection mode
- The API was down, so the system could not clear the challenges
The CTO summed it up directly: Cloudflare made a configuration change that triggered a latent bug, which started a chain reaction that degraded the network. The issue was not an attack and has now been resolved.