









Apparently, the streaming business model isn’t as recent an invention as we’ve been led to believe. It was in existence in a certain form, a while before the Internet – as we know it today, was invented.
In 1982, a man named Dieter Seitzer, Professor für Technische Elektronik an der Universität Erlangen-Nürnberg (Professor of Technical Electronics at the University of Erlangen-Nürnberg) applied for a patent for a “Digital Jukebox”, one through which content consumers could dial into a centralized computer server, then use the keypad to request music over the then new digital telephone lines being installed across Germany.

Rather than pressing millions of disks into jewel cases and distributing them through stores and other physical outlets, everything would be saved in a single electronic database and accessed as needed. A subscription based service such as this would skip the many inefficiencies of physical production and distribution by hooking the stereo input directly to the phone. Brilliant, right?
The patent was rejected because the digital phone lines at the time were rather primitive, and such an enormous amount of audio data would never have fit in such a narrow ‘pipe’ without a killer compression algorithm – one as revolutionary as MPEG-3 (MP3) which typically has a compression ratio (depending on the bitrate) of around 12:1.
Lossy compression algorithms like MP3 are only effective because the human ear is designed to (or has evolved/adapted to, depending on your standpoint about evolution vs. creation) receive and process only a limited range of auditory data, the rest of which is discarded, and thus lies the premise of the Karlheinz Brandenburg MP3 compression algorithm. The compressed version is merely an approximation – one that has removed information that your ear-brain combo will have glossed over anyways, to varying degrees, depending on your chosen bitrate (for the more visually inclined, read: resolution).
On the subject of bitrate, information in the digital age is/was stored in binary units, called “bits”, and to store 1 second of uncompressed CD audio data, you needed 1400000 bits (1.4megabits per second, 1.4mbps), and Dieter Seitzer’s goal was to store 1 second of audio information in as little as 128000 (128kilobits per second, 128kbps).
If you are like me, and you’re wondering how Dieter Seitzer and his rockstar protege, Karlheinz Brandenburg achieved such mind boggling compression ratios, look no further than a clever implementation of the results of two other great scientists – Karl Eberhard Zwicker (father of Psycho-acoustics), and David Huffman (1950s MIT Computer scientist).
Zwicker’s Four Psychoacoustic Tricks
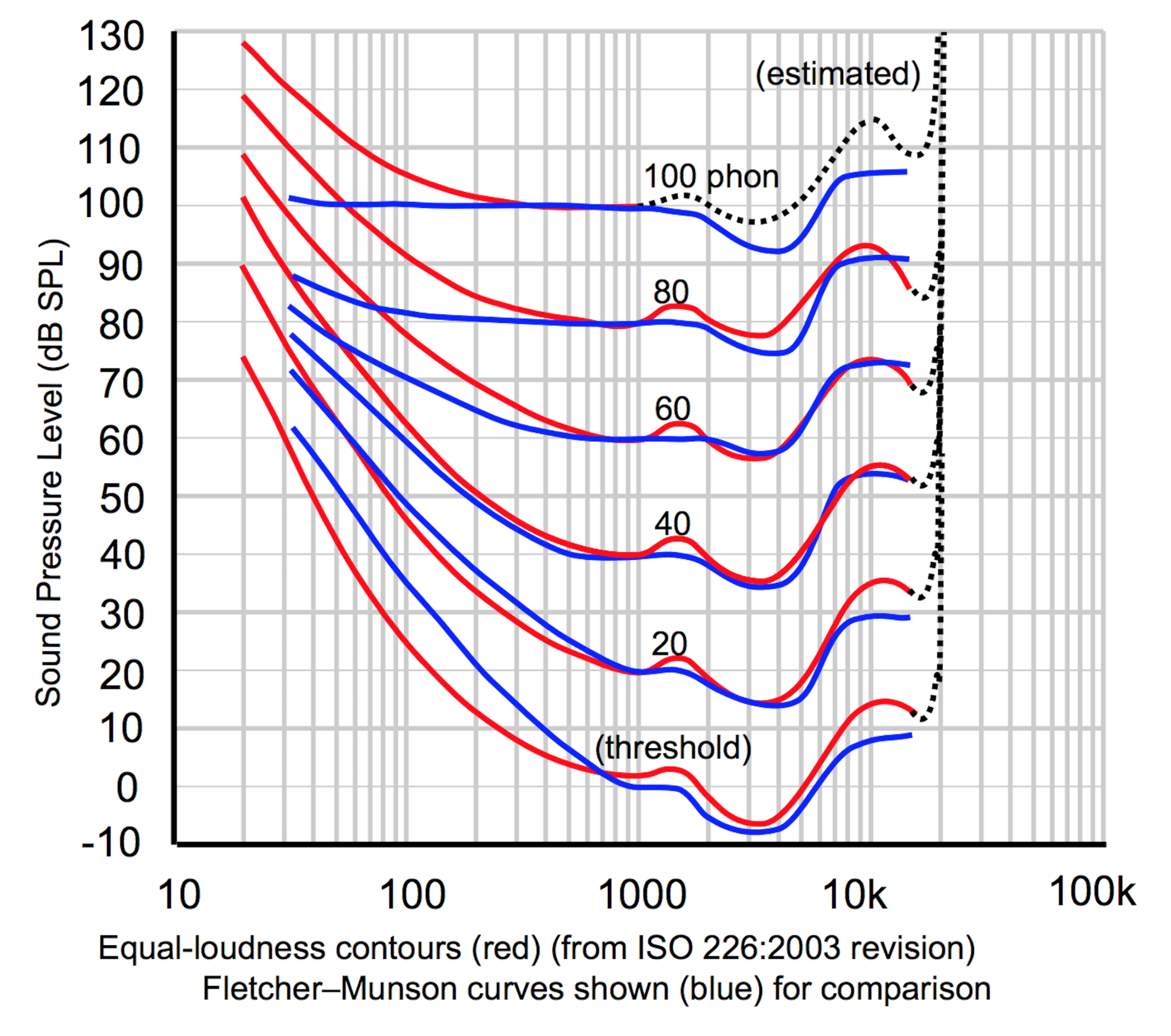
1: Zwicker had realized that human hearing was most sensitive at a certain range of frequencies, 1kHz (search Google for the ‘Fletcher-Munson curve‘, if you’re interested), and in registers beyond that, hearing degraded progressively till you got to 20kHz, beyond which human hearing fails. This means that as you went higher on the scale, you could assign fewer bits to the extreme ends of the spectrum (because, well, the ear would discard all that information anyways.
2: Zwicker also showed that tones close to each other on the frequency spectrum cancelled out, and lower, louder tones cancelled out higher, lighter ones, so in a Cello and Violin ensemble, you could get away with assigning fewer bits to the violin, or in a piano sonata, assigning fewer bits to higher pitched notes, and in both cases, still get close to the original sound.
3: Zwicker also found that noise a few milliseconds after a loud bang or click were cancelled out, and so you could assign fewer bits to those parts as well. So, if you had a cymbal crash every few measures, you could assign fewer bits to it.
4: Strangely, auditory data prior to a loud bang was also ignored by the brain, because it takes a few milliseconds to actually process what the ear was sensing, and this processing could be disrupted by a sudden onrush of loud noise, so it makes sense to assign fewer bits to the first few milliseconds before the beat.

While, at the time, this was a groundbreaking system, the real discovery was Brandenburg figuring out that you could run this process iteratively, and so if you wanted even smaller sizes, you could repeatedly apply these “filters” and sacrifice even more audio fidelity for smaller sizes, which were very necessary back then.
Of course, not all music was so complex as to make Zwicker’s method completely useful on its own, and this is where Huffman’s method (termed Huffmann coding) came in.
Huffman Coding
This approach was developed by pioneer MIT Computer Scientist, David Huffman in the 1950s. Huffman discovered that if you wanted to save bits, you had to look for repeated patterns because removing redundancy, by definition means that you use up less space for the same output, with a small margin for error. This meant that rather than assign bits to a pattern each time it occurred, you needed to do it just once, and refer back to those bits whenever they were needed. So, if you tried to compress a violin concerto, for example, the processor would take a tiny sample of the violin sound, complete with harmonics, and repeat it until a different note or articulation is played.
These two methods complemented each other perfectly – Zwicker, for complex pieces, and Huffman for the simpler, more monotonous ones, and the end result was an application of decades of research into human anatomy, math and acoustic physics. By around 1986, Brandenburg had written a rudimentary computer program to implement his solution, and this formed a lot of the basis of digital audio, as we know it today.
To be continued…
Photo Credit: Donald Durham, Jim Allen via Compfight, Wikipedia cc







