









Open-source model with unlimited context, real-time accuracy scoring, native tool calling, and adaptive compute. Targets emerging markets where cloud dependency is not viable.
Alchymia Labs today released Regent https://alchymia-ai.github.io/Regent/, a language model built for workloads where the cost of a wrong answer is measurable, environments where errors have a high price tag. The model produces a real-time confidence score for every word it generates, reasons through complex questions before answering, calls external tools natively, and operates fully offline on locally owned hardware. It is available open source at the 3B, 7B through 50B parameter scale. A commercial frontier-scale version, Grande Regent, covering 70B through one trillion parameters, will be distributed through Alchymia Groom.Regent is the first production language model to come out of Africa. Not a fine-tune of an existing model or a wrapper around another provider’s API. It is a ground-up architecture designed to be on par with the best models in the world at the workloads it is built for.
Regent addresses two structural limitations of current AI deployment that have constrained adoption in accountability-sensitive sectors and prevented meaningful adoption in emerging markets.
A different architecture
Every frontier language model in production today, including GPT-5, Claude, Llama, Mistral, and Gemini, is built on the transformer architecture from a 2017 paper. They differ in scale and training data, but the underlying engine is the same.
Regent is not a transformer. It is a Mamba-2 state-space model with grouped-query attention at selected layers. This is a fundamentally different computational engine that enables properties transformers cannot provide at any scale: fixed memory regardless of conversation length, native structured knowledge input, and real-time accuracy scoring built into the architecture rather than added as a post-processing layer.
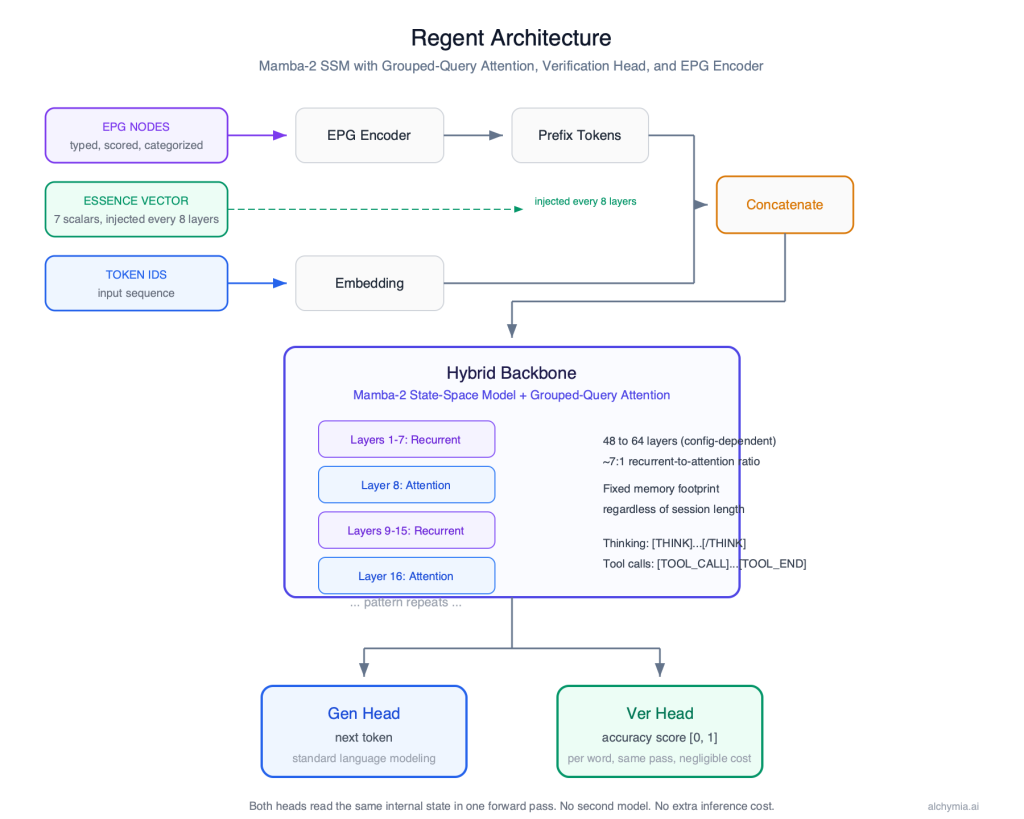
Real-time accuracy scoring
Every language model in production today generates output and leaves verification to downstream processes: human review, secondary model passes, or sampling-based consistency checks. These approaches add cost and latency, and none operate at the moment of generation.
Regent produces a per-word confidence score as a native output alongside generated text. When confidence falls below a configurable threshold, the model does not continue writing. It stops, retrieves relevant information from its structured knowledge store, and regenerates from the uncertain point. This behavior is built into the architecture, not added as a post-processing layer.
The accuracy scoring capability adds less than 0.1 percent to the model’s total parameter count and runs within a single generation pass. There is no additional inference cost relative to a model without this capability.
Thinking and tool calling
Regent reasons through complex questions before responding. When a query requires multi-step thinking, the model produces an internal chain of reasoning, then delivers the answer. The reasoning is visible to the caller and can be used for audit, debugging, or compliance review.
The model also calls external tools natively. When it determines it needs information from an API, database, or search engine, it emits a structured tool request, pauses generation, receives the result, and continues. This operates through dedicated tokens in the architecture, not through a plugin system.
Adaptive compute allocation
Regent includes an adaptive gate at each attention layer. The model learns per-token whether its attention pathway is needed for long-range dependency resolution or whether its recurrent backbone is sufficient. During routine generation, attention is skipped. During complex reasoning, it fires at full capacity.
The result is lower inference cost in production, faster responses on routine queries, and no quality degradation on hard questions. The model allocates its own compute based on what each token actually requires.
Live knowledge, no retraining
The model accepts structured knowledge as native input on every request. This is read directly by the model at inference time. It is not baked into weights during training.
When knowledge changes, the model reflects it on the next request. A new drug interaction, a crop disease outbreak, a fraud pattern, updated AML/KYC rules, a sanctions list change, a commodity price shift, an equipment fault code, a patient history update, a route hazard, a newly published ruling. Any industry where decisions depend on current information. No retraining required. No model update to wait for. For organisations operating in fast-moving clinical, defence, financial, agricultural, or regulatory environments, this is the difference between AI that is current and AI that is months behind.
Other models require retraining to incorporate new information. That process takes months and costs millions. Regent reads it directly.
For the majority of enterprise deployments currently using Retrieval-Augmented Generation (RAG), this is a direct replacement. RAG requires a vector database, an embedding pipeline, a chunking strategy, and a retrieval step that frequently misses relevant context or returns irrelevant results. Regent eliminates that entire layer. Knowledge enters the model structured, typed, and scored through a dedicated encoder. The model distinguishes high-confidence facts from low-confidence ones natively. When uncertain, it retrieves from the knowledge graph automatically at the point of uncertainty. No vector search, no context window pressure, no re-injection cost per request.
Deployment without cloud dependency
Current frontier AI models operate as services. Pricing is per-token, infrastructure is cloud-based, and ongoing access requires internet connectivity and subscription fees denominated in major currencies.
Regent is distributed as weights and code. Organisations license the model once and deploy it on their own hardware. There are no per-inference fees after deployment. The model operates fully offline. The 3B, 7B parameter version runs on edge hardware in the sub-$1,000 range. Larger configurations scale to single-server deployment.
This changes the economic model for organisations in markets where cloud API pricing is not viable at scale: public health systems, government ministries, legal aid organisations, agricultural cooperatives, and industrial operators across sub-Saharan Africa, South and Southeast Asia, and Latin America.
OpenAI-compatible API
Regent exposes an OpenAI-compatible API endpoint at /v1/chat/completions. Any application, SDK, or framework built for OpenAI’s chat completions API works with Regent by changing the base URL. No code changes, no new SDK, no integration project.
Market focus
Regent is positioned for sectors where the cost of an inaccurate output is quantifiable, where data sovereignty or operational constraints make cloud dependency unacceptable, or where unlimited context and fixed memory create a structural advantage.
Legal research requires every claim to be traceable to a source. Financial research, fraud detection, and AML/KYC require AI output to be auditable before it influences decisions. Clinical decision support requires confidence scoring that meets healthcare compliance requirements and multi-hour patient encounters without memory degradation. Government and defence deployments require air-gapped operation with no external data exposure.
The same architecture properties apply across pharmaceutical and drug development, where regulatory submissions require claim-level auditability and trial data cannot leave a jurisdiction. Nuclear and critical infrastructure, where air-gap and long-shift operation are mandatory. Maritime and offshore, where vessels operate without connectivity for weeks. Mining and extraction, where remote sites have no reliable infrastructure. Insurance and claims, where every decision requires a traceable justification for regulatory review. Emergency services, where the model must operate when infrastructure is unavailable. Audit and financial forensics, where every figure needs a source. Agriculture, where zero marginal cost after deployment is the only viable model for organisations operating on thin margins without reliable internet.
Code generation benefits from the same properties. The model holds an entire repository in context with no limit, calls compilers, test runners, and linters natively through tool calling during generation, and scores confidence on every line of generated code before the developer runs anything. Multi-hour coding sessions do not degrade.
Consumer chat is well served by the fixed memory and adaptive gate. Conversations never truncate. Routine exchanges cost less compute. Grande Regent at 70B+ is competitive with frontier models on general tasks.
Advanced code generation
The same architecture properties that serve legal, clinical, and industrial workloads apply directly to code generation. Current code models operate within a fixed context window, typically 128K – 1M tokens. A mid-size or enterprise-level codebase exceeds that limit. The model sees fragments of the project, not the whole.
Regent holds the entire repository in its state with no context limit. The model calls compilers, test runners, linters, and type checkers natively through tool calling during generation, receives the results, and fixes the code in the same pass. The verification head scores confidence on every line of generated code in real time, distinguishing between code the model is confident about and code it is guessing at, before the developer runs anything.
Fixed memory means multi-hour coding sessions do not degrade. The model retains the full project state from the first edit to the last. No other code model combines full-project context, native toolchain integration, and per-line confidence scoring.
Developing economies and the 10x imperative
The markets where Regent matters most are the ones where AI has the highest potential impact and the lowest current penetration: healthcare access in sub-Saharan Africa, legal services across South Asia, agricultural decision support in Latin America, and financial inclusion in Southeast Asia.
These are not secondary markets. They are the majority of the world’s population. The reason AI has not reached them is not capability. It is economics and infrastructure.
Alchymia’s position is that closing this gap does not happen through incremental improvement. It requires building at a fundamentally different level of ingenuity. Not 2x. 10x. That is the operating requirement when you start without the capital, infrastructure, or institutional advantages that the incumbents have. It is also the core ethos of the people at Alchymia.
Distributed Shared Training Protocol
Alchymia is developing DSTP, a Distributed Shared Training Protocol, designed to enable training models at 1 to 2 trillion parameters by pooling compute across institutions and geographies. Universities, national labs, government compute centres, private organisations, and individuals contribute capacity to a shared training run without centralising all hardware in one location.
The goal is structural: frontier-scale AI should be achievable without a single nine-figure infrastructure investment. DSTP is in active development.
Regent and Grande Regent
Regent, the open-source tier at 3B, 7B to 50B parameters, is designed for the broadest possible deployment, including organisations in markets where commercial licensing is not economically viable. Releasing this tier as open source is a deliberate choice: the organisations that need this most are often the ones least able to pay for it.
Grande Regent, at 70B to one trillion parameters, is a commercial product for organisations that require frontier-scale performance and direct enterprise support. It shares the same architecture as open-source Regent. Workflows built on Regent can migrate to Grande Regent without changes to the integration layer. Grande Regent is distributed through Alchymia Groom with commercial licensing, production-grade tooling, and enterprise SLAs.
Coming next: Darkhorse
In the coming months, Alchymia will introduce Darkhorse: the Large Language Action Model (LLAM), first generation. Alchymia’s flagship and most capable generalist AI. Darkhorse is designed to decide and execute. Multi-step tasks completed end-to-end. Millions of tokens of context with compact memory efficiency. Makes decisions and acts on them.
Current AI agents are chat models with external orchestration: prompt chains, retry loops, and tool frameworks built outside the model because the model was never designed to act. Darkhorse is an action model from the ground up. Decision-making and execution are native, not scaffolded. It will change how agents are built and what they are capable of.
About Alchymia AI Research Labs
Alchymia AI Research Labs is an AI research organisation founded by Ayomide I. Daniels (https://www.linkedin.com/in/prime-architect/). The team is in the diaspora. The organisation is focused on researching, building, and accelerating AI for developing economies.
The organisation’s position is that the majority of the population that will benefit most from AI, in healthcare access, legal access, agricultural productivity, financial inclusion, and education, is located in markets where per-token cloud pricing creates a permanent structural barrier.
The mandate is not to build cheaper versions of existing models. It is to build models with properties that existing models do not have, and to distribute them as infrastructure.
Regent ships with a browser-based interface called Model Studio that manages the complete model lifecycle. From a single interface, teams can source and prepare training data from web URLs or HuggingFace datasets, run all four training phases with live output monitoring, inspect and resume from any checkpoint, run inference against the model with full control over its behavioural parameters and knowledge graph, and export the finished model directly to HuggingFace or as a self-contained Docker package. Organisations without a dedicated machine learning infrastructure can take a model from raw data to deployment without writing a line of code.









